1 x 1 convolution
논문을 읽다가 1 x 1 convolution 이란걸 보게되었습니다.
1 x 1 convolution이 뭘까? 궁금해서 찾아본것을 바탕으로 정리해보겠습니다.
Neural Network연산을 할때 feature map들의 채널을 줄이는 연산을 많이 진행합니다.
다음과 같은 연산을 보겠습니다.
5 x 5 filter convolution 연산
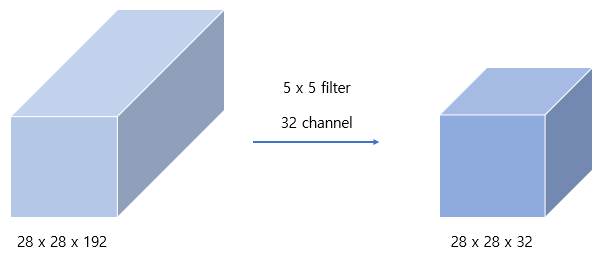
연산량은 28 x 28 x 32 x 5 x 5 x 192 = 120,422,400 약 1.2억 번의 연산이 필요합니다.
여기서 1 x 1 convolution을 사용하여 channel을 줄인뒤, 5 x 5 filter convolution을 적용해 보겠습니다.
1 x 1 convolution을 이용한 5 x 5 convolution 연산
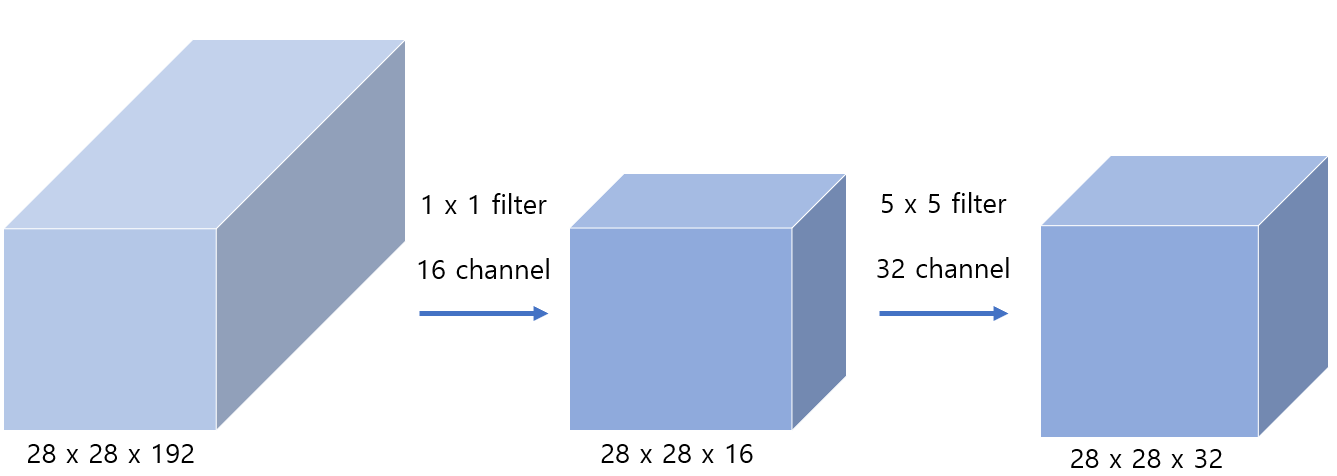
우선 첫번째로 채널을 줄이는 연산량은 28 x 28 x 16 x 1 x 1 x 192 = 2,408,448 약 240만 번의 연산이 필요하며,
다시 32 채널로 늘릴때는 28 x 28 x 32 x 5 x 5 x 16 = 10,035,200 약 1000만번의 연산이 필요합니다.
따라서, 총 약 1240만번의 연산이 필요하게 됩니다.
같은 5 x 5 filter를 적용한 연산임에도 불구하고 연산량은
1.2억번(12000만번) 과 1240만번의 연산으로 10배가까이 차이나는것을 확인할 수 있습니다.
그럼, 과연 실제로도 그정도 연산속도 차이가 있을까요?
Tensorflow를 통해 실험해 보겠습니다.
1. MNIST 불러오기
from tensorflow import keras
(train_images, train_labels), (test_images, test_labels) = keras.datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images, test_images = train_images / 255.0, test_images / 255.0
우선 mnist를 불러온뒤에 convolution을 사용하기위해 이미지를 reshape를 통해 모양을 바꾸고 정규화하겠습니다.
2. 모델 정의하기
모델을 5 x 5 convolution만 사용한 모델과 1 x 1 convolution을 활용한 모델 2개를 정의하겠습니다.
model = keras.models.Sequential([
keras.layers.Conv2D(192, (3, 3), activation='relu', padding='SAME', input_shape=(28, 28, 1)),
keras.layers.Conv2D(1024, (5, 5), activation='relu', padding='SAME'),
keras.layers.Flatten(),
keras.layers.Dense(10, activation='softmax')
])
model2 = keras.models.Sequential([
keras.layers.Conv2D(192, (3, 3), activation='relu', padding='SAME', input_shape=(28, 28, 1)),
keras.layers.Conv2D(16, (1,1), activation='relu', padding='SAME'),
keras.layers.Conv2D(1024, (5, 5), activation='relu', padding='SAME'),
keras.layers.Flatten(),
keras.layers.Dense(10, activation='softmax')
])
실험에서는 좀더 차이를 확실하게 보기위해 32채널이아닌 1024채널을 사용하겠습니다.
3. summury( ) 함수를 통해 정보 확인
model.summary()
model2.summary()

각 모델의 parameter의 수를 보면 약 3배정도의 parameter의 차이를 보입니다.
4. 모델 훈련하기
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model2.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5)
model2.fit(train_images, train_labels, epochs=5)
각 모델의 optimizer와 loss를 정의하고, 실제로 훈련을 진행합니다.


실제로 실험을 해본 결과는 10배나 5배 빠른 정도로 차이가있지는 않았고, 30% ~ 40% 정도의 차이를 보입니다.
gpu환경과 cpu환경의 차이가 있나 궁금해서 cpu환경에서 한번더 실험을 진행했습니다.

하지만, cpu환경에서 실험을 해본결과는 약 5배정도의 속도차이를 보입니다.
accuracy에서는 큰차이가 없는걸로 보아, 성능에는 큰 차이가 없는걸로 확인됩니다.
5. inference 속도 차이
model.evaluate(test_images, test_labels)
model2.evaluate(test_images, test_labels)
inference의 속도도 한번 비교해보겠습니다. 각 모델을 3번씩 inference를 진행해보겠습니다.


inference에서는 간극이 더 줄어 20% ~ 30%의 성능차이를 보였습니다.
따라서, 이론적으로 계산했던 10배이상의 차이는 보이지 않으며 20~30%정도의 속도 상승을 보이는것을
확인할 수 있었습니다.
하지만, GPU환경이 아닌 CPU환경에서는 좀더 이론에 가까운 5배정도의 차이를 보이는것을 확인할 수 있었습니다.
'Deep Learning' 카테고리의 다른 글
| Single Layer Perceptron (SLP) (0) | 2019.11.05 |
|---|